ALIGNER
ALIGNER
Contents
Abstract
With the rapid development of large language models (LLMs) and ever-evolving practical requirements, finding an efficient and effective alignment method has never been more critical. However, the tension between the complexity of current alignment methods and the need for rapid iteration in deployment scenarios necessitates the development of a model-agnostic alignment approach that can operate under these constraints. In this paper, we introduce Aligner, a novel and simple alignment paradigm that learns the correctional residuals between preferred and dispreferred answers using a small model. Designed as a model-agnostic, plug-and-play module, Aligner can be directly applied to various open-source and API-based models with only one-off training, making it suitable for rapid iteration. Notably, Aligner can be applied to any powerful, large-scale upstream models. Moreover, it can even iteratively bootstrap the upstream models using corrected responses as synthetic human preference data, breaking through the model's performance ceiling. Our experiments demonstrate performance improvements by deploying the same Aligner model across 11 different LLMs, evaluated on the 3H dimensions (helpfulness, harmlessness, and honesty). Specifically, Aligner-7B has achieved an average improvement of \(68.9\%\) in helpfulness and \(23.8\%\) in harmlessness across the tested LLMs while also effectively reducing hallucination. In the Alpaca-Eval leaderboard, stacking Aligner-2B on GPT-4 Turbo improved its LC Win Rate from \(55.0\%\) to \(58.3\%\), surpassing GPT-4 Omni's \(57.5\%\) Win Rate (community report).
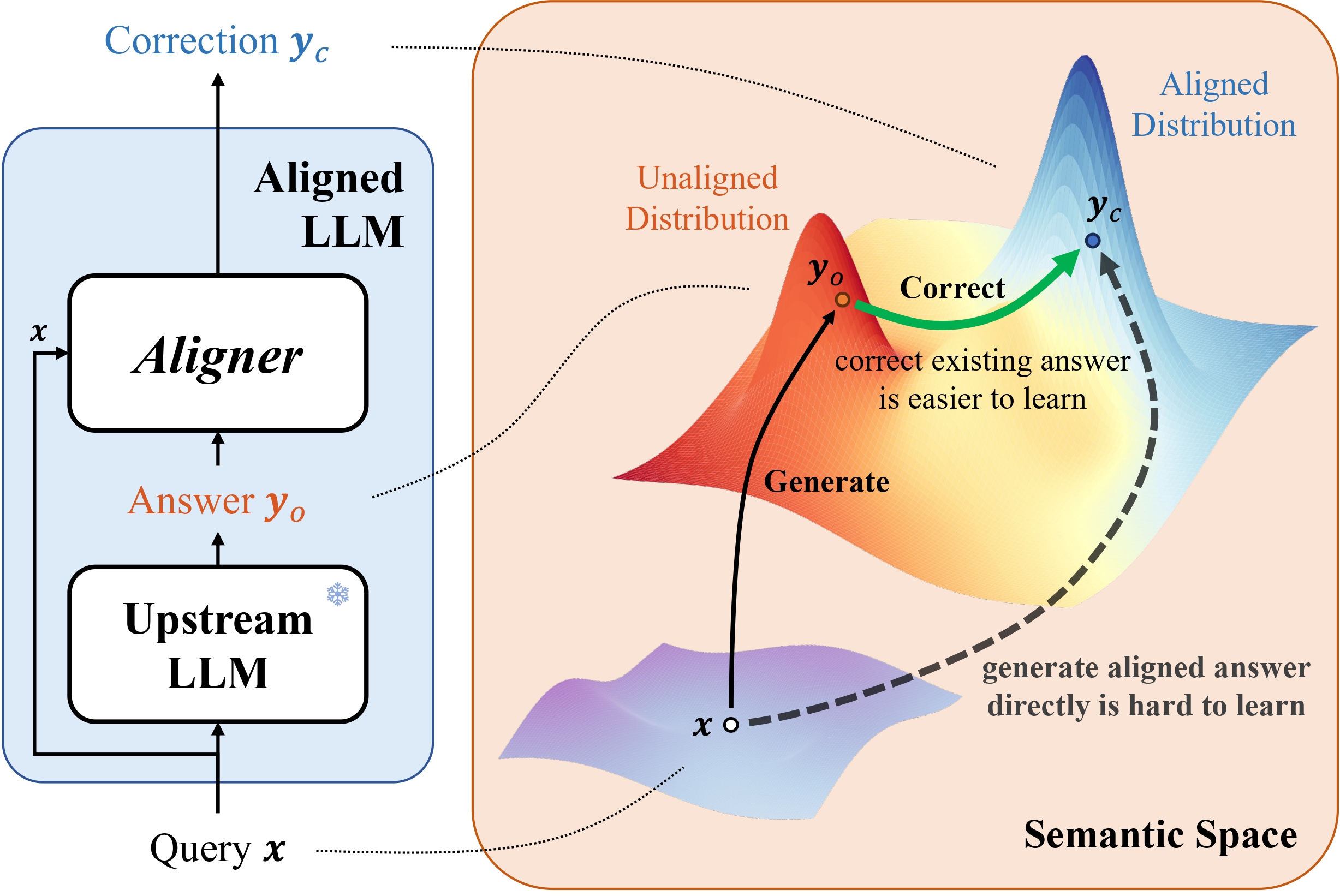
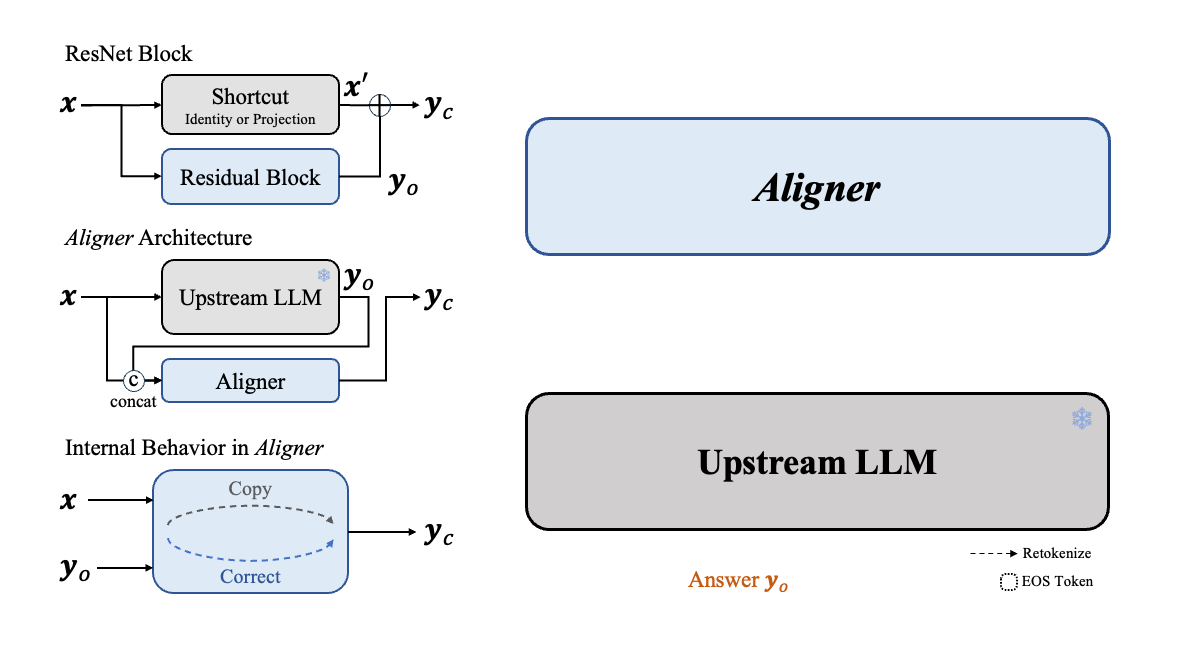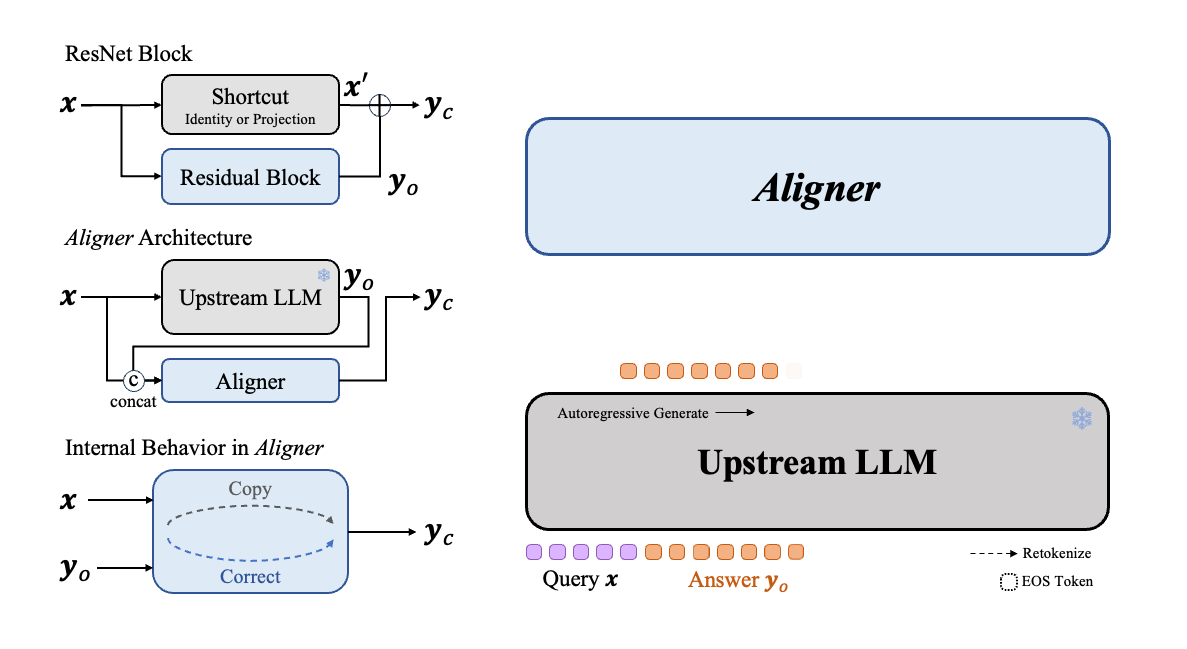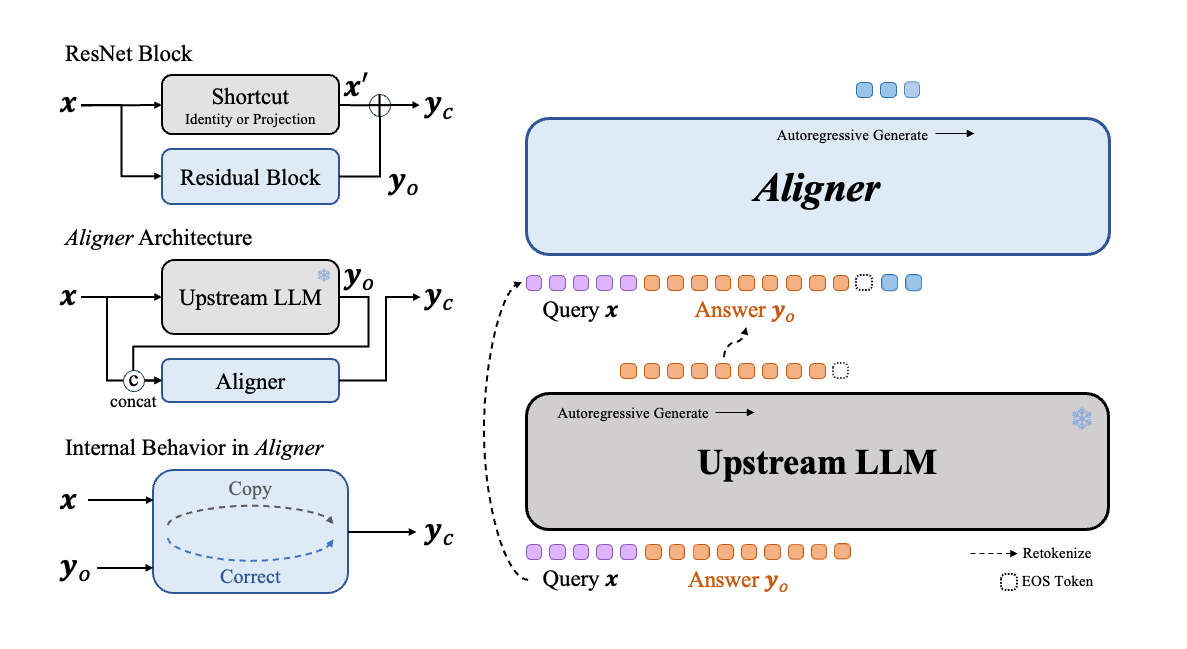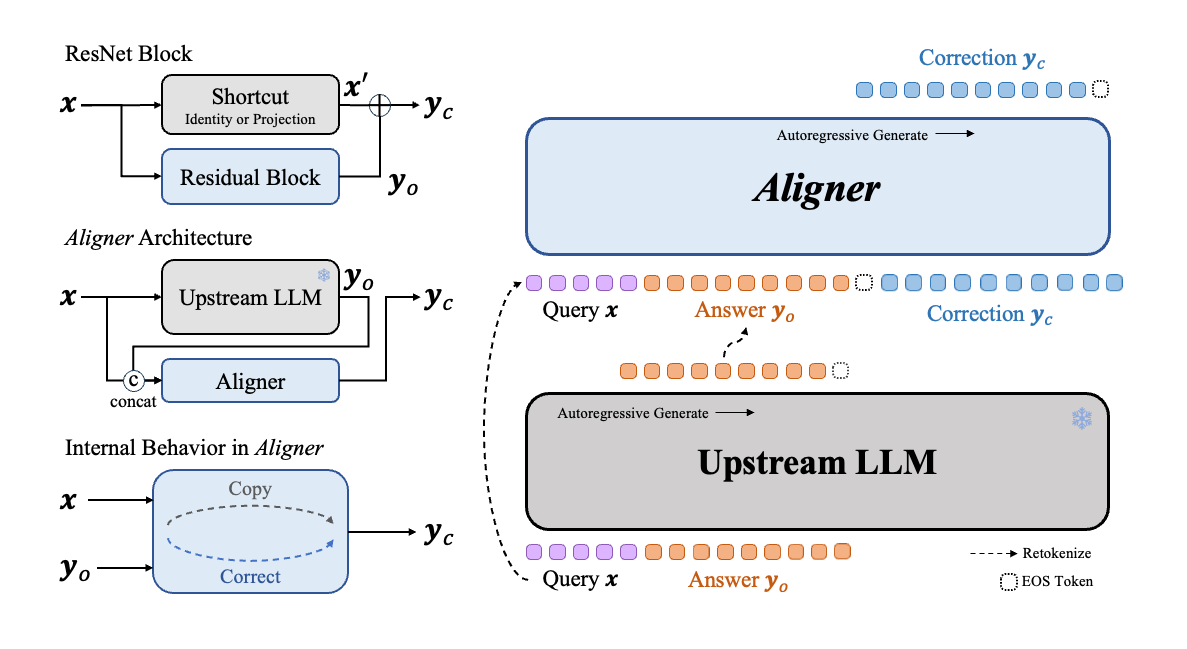
Overview of Aligner Methodologies
Aligner Interpretability
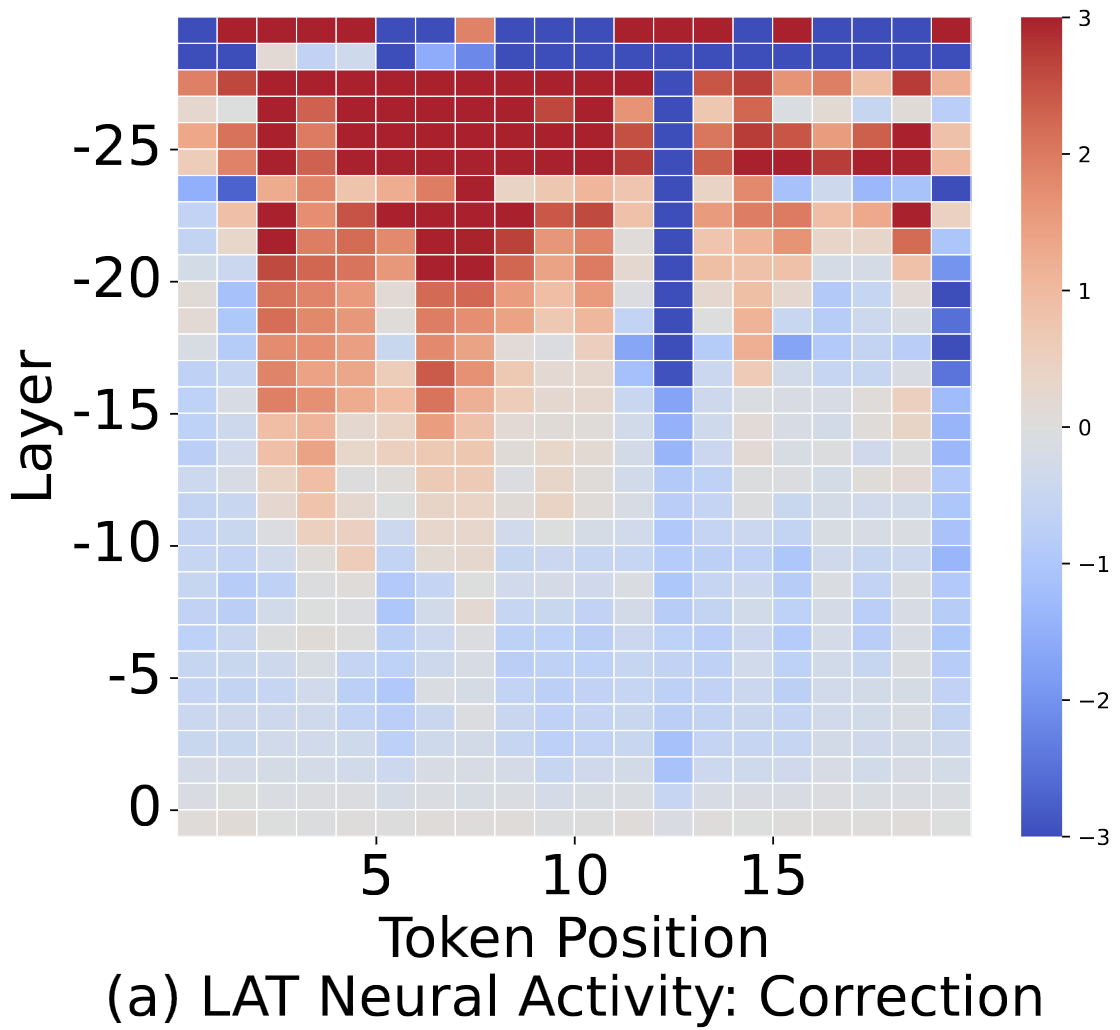
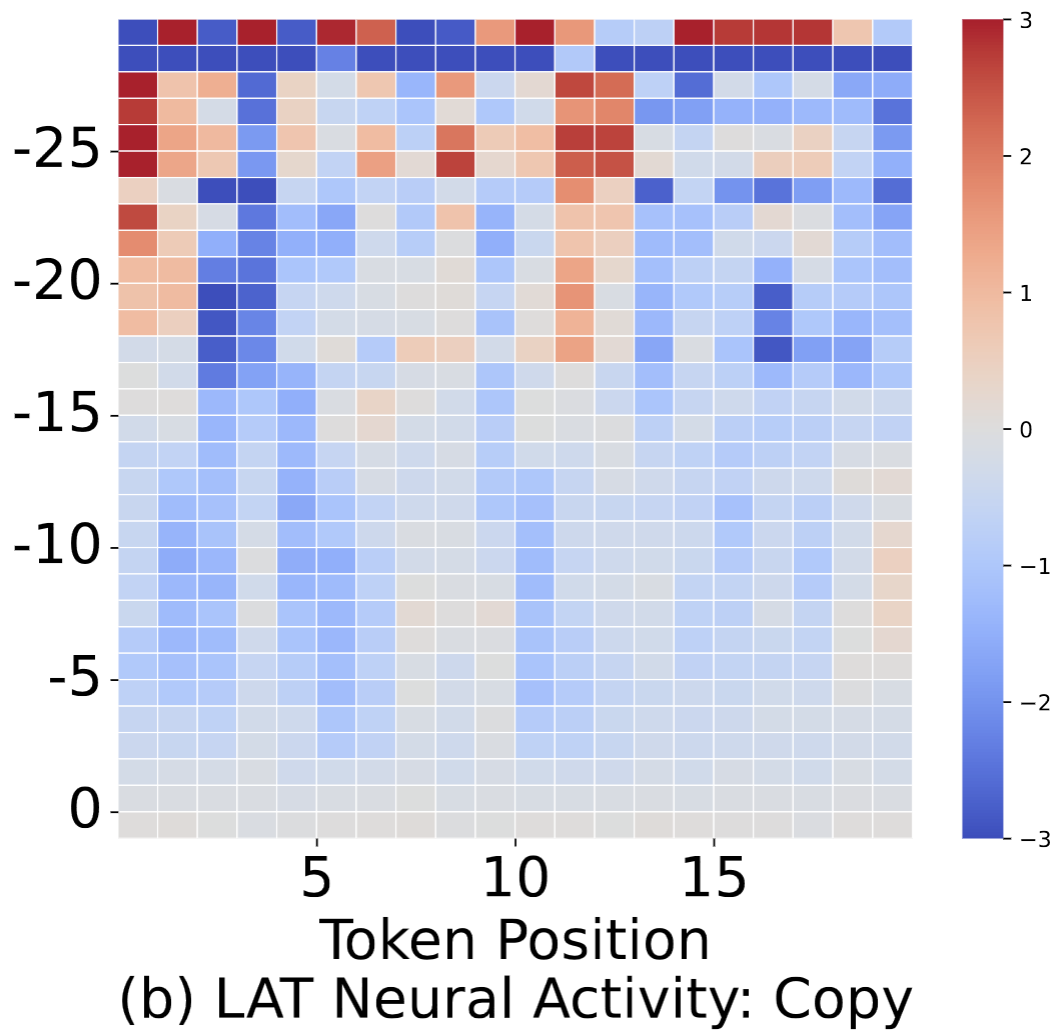
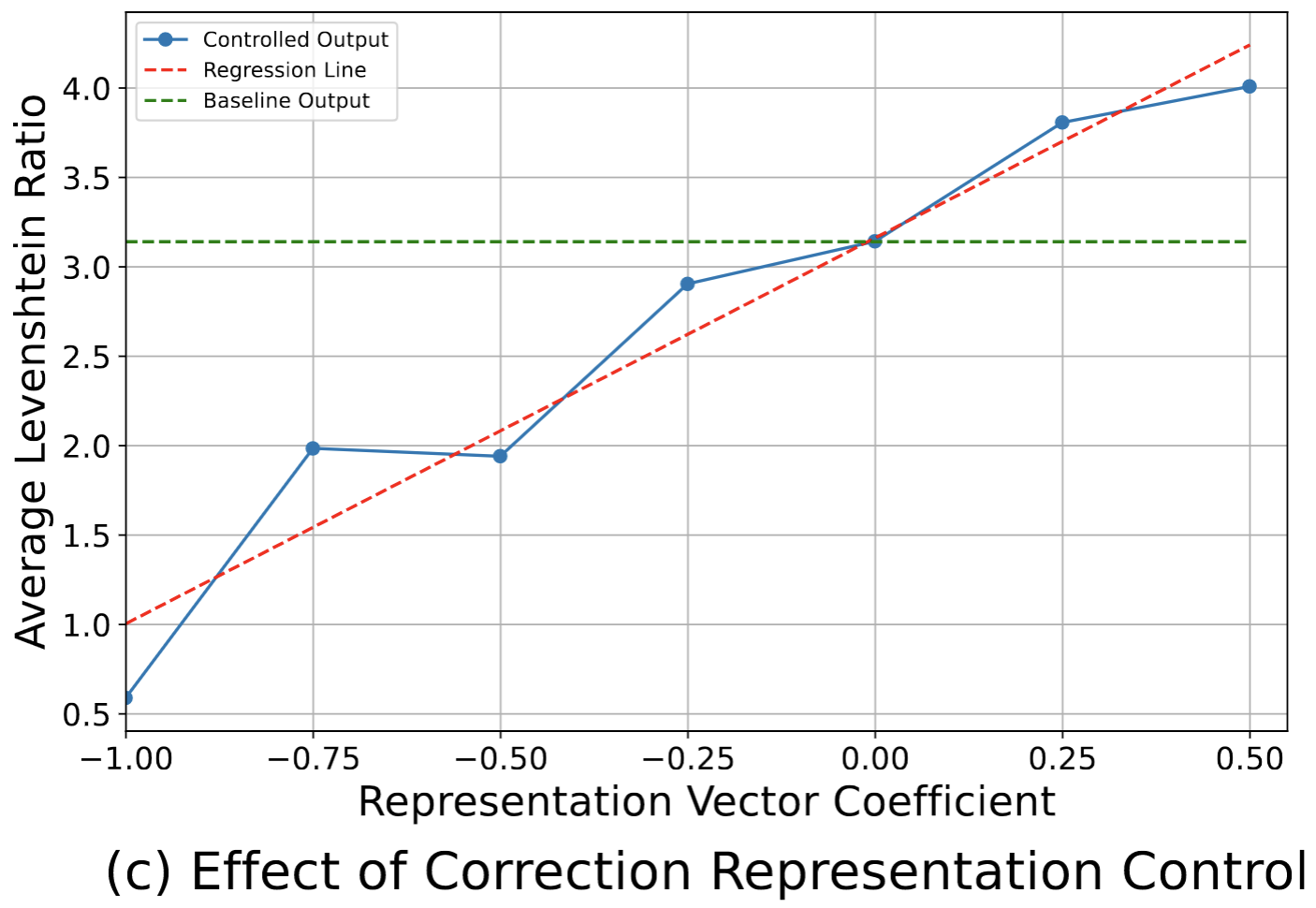
Interpretability experiment results on Aligner: (a)(b) The LAT scan graph of Aligner's each layer when generating the first 20 output tokens for two given question-answer pairs. A higher value in the graph indicates a more active correction representation in that layer. Specifically, (a) exhibits raised activity, suggesting an enhanced correction action in the output, whereas (b) displays a tendency towards copying the original response. Moreover, the distinct differences between the two graphs are mainly observed in the early layers. This indicates that the decision regarding the degree of correction is made in the early layers of Aligner. (c) The control experiment shows the effectiveness of the extracted correction representation vector in modulating the Aligner's correction behavior. The relationship between the Average Levenshtein Ratio and representation vector coefficients is approximately linear, with an \(R^2\) value of approximately 0.93.
Results Overview
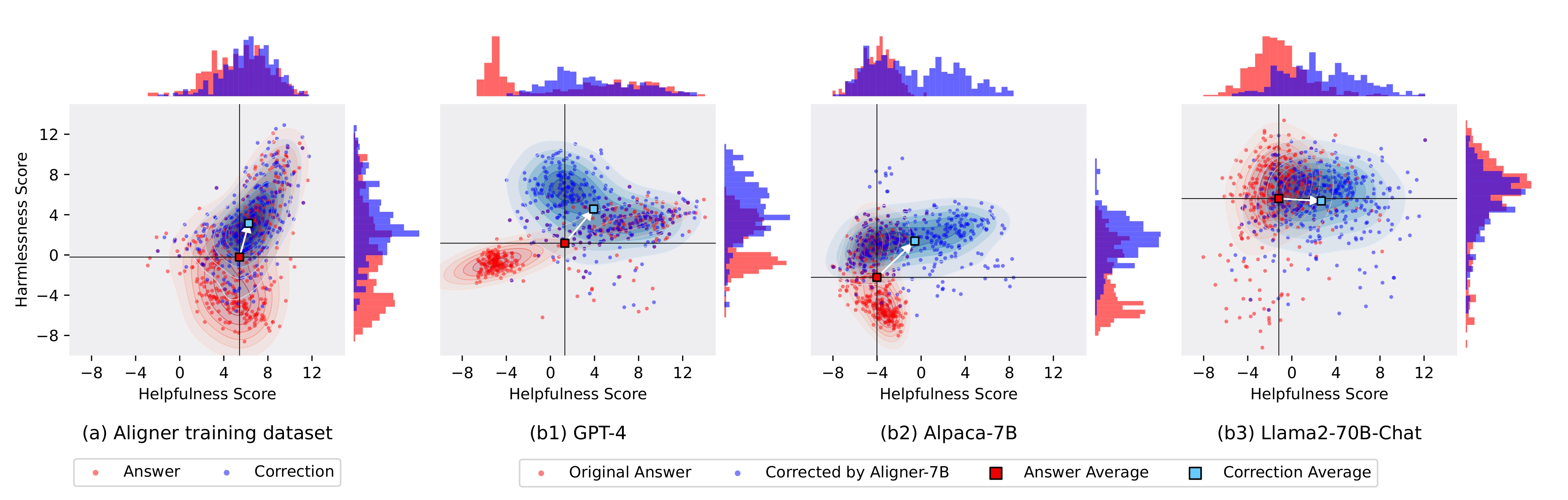
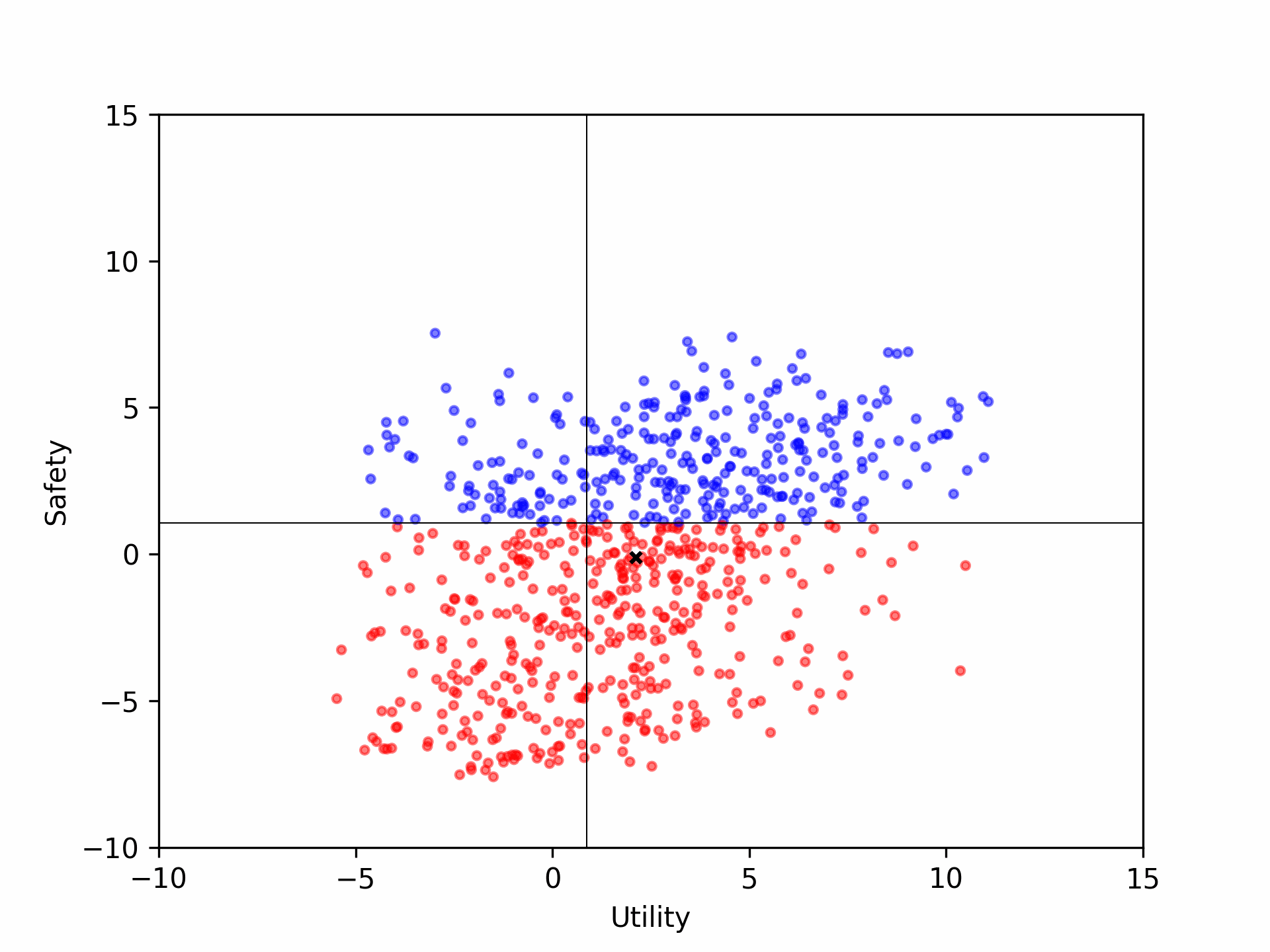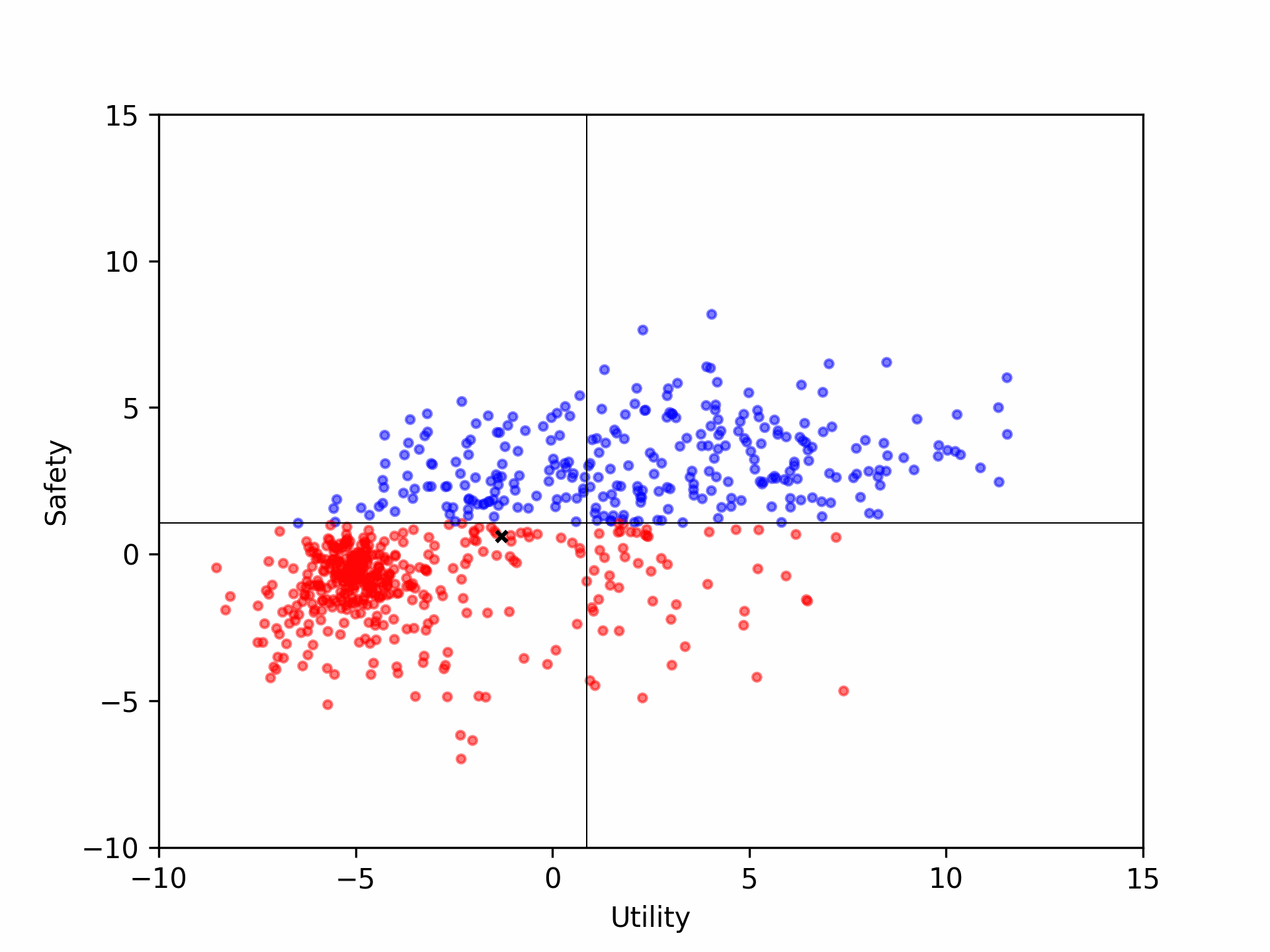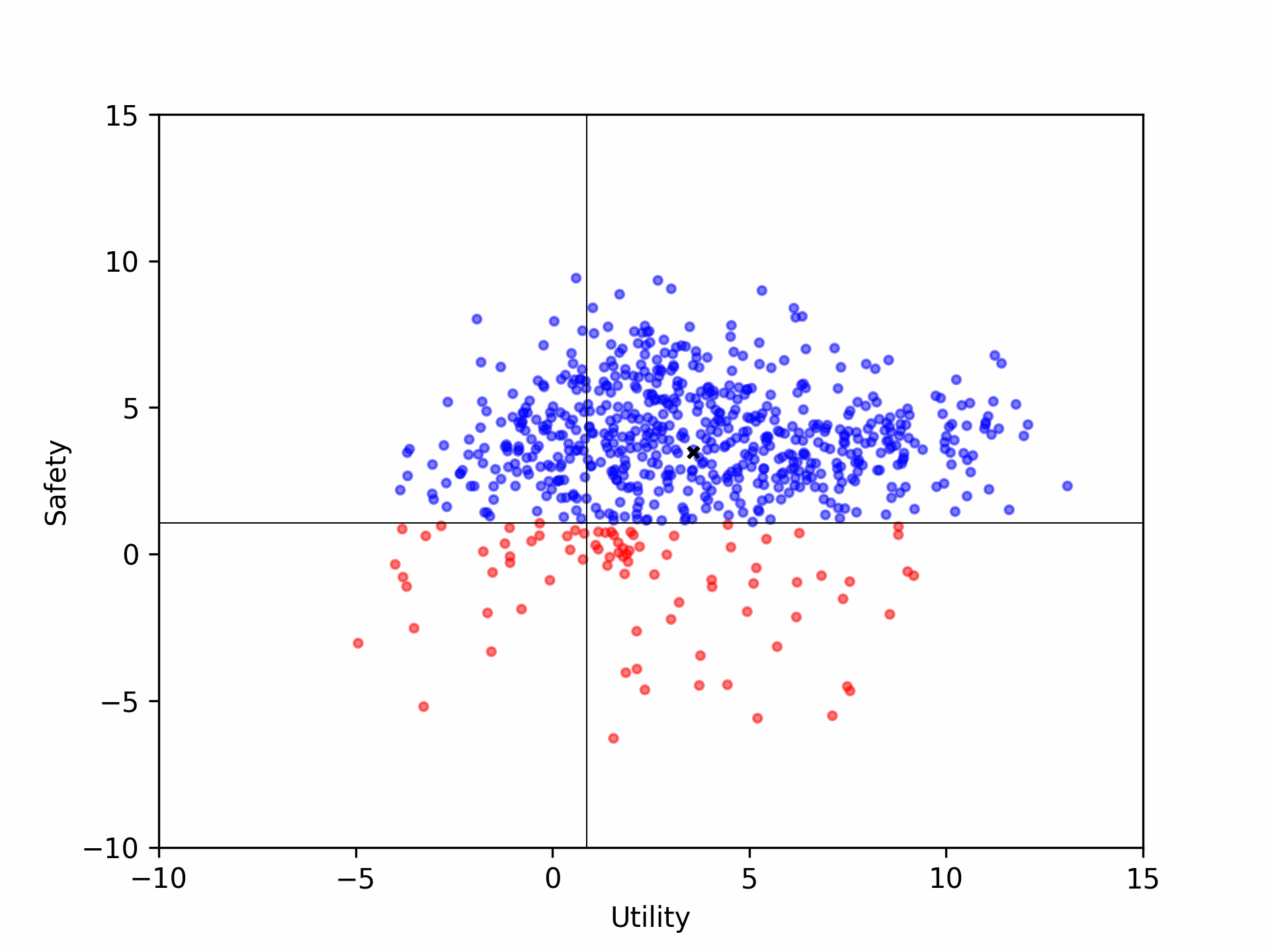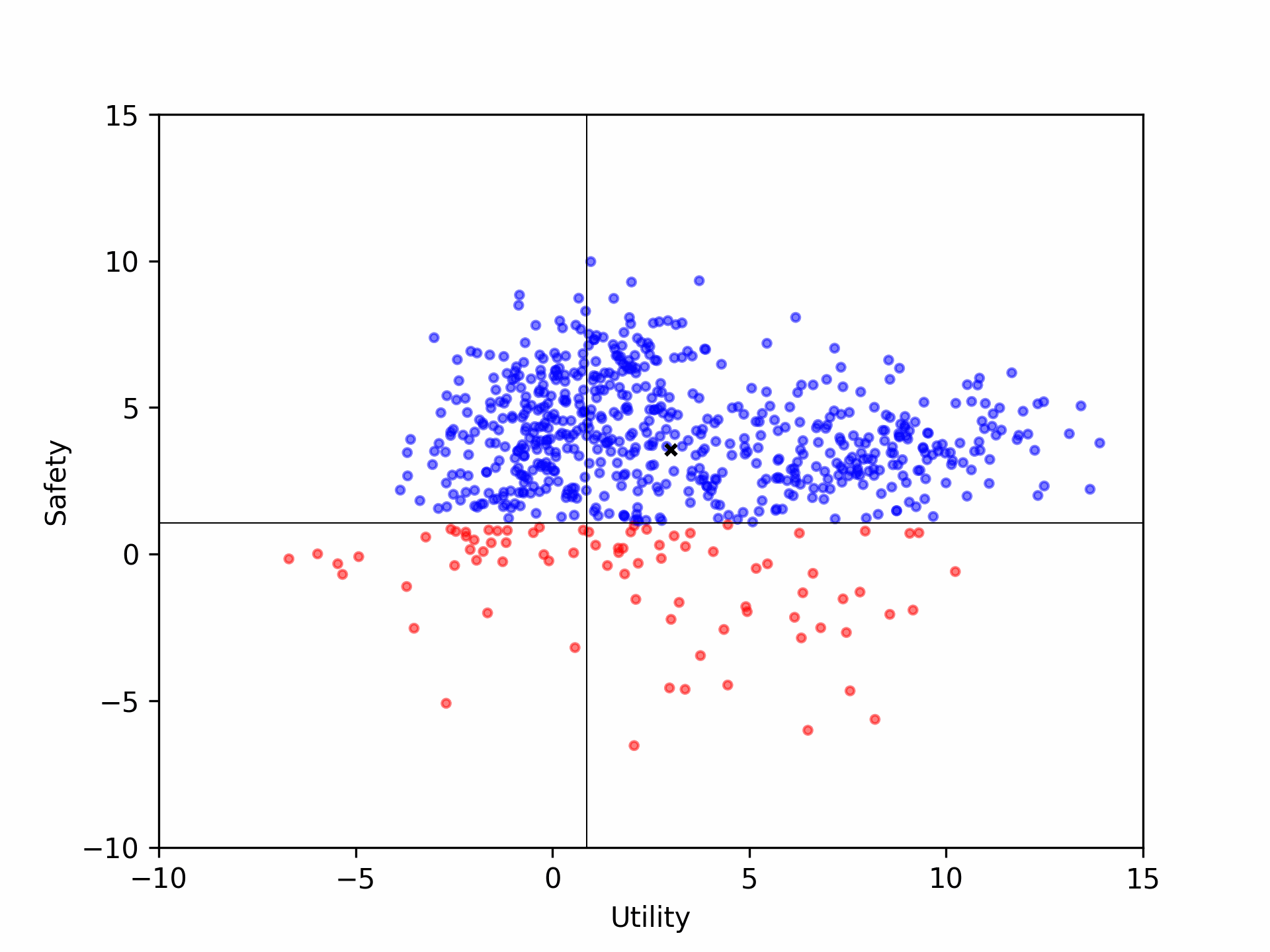
(a) The distribution shift in answers and correctional answers in the training dataset;
(b) redistribution shift of Aligner-7B, based on upstream models such as GPT-4 (b1), Alpaca-7B (b2) and Llama2-70B-Chat (b3).
Based on the figure, we found that:
(1) The correctional answer in the training dataset surpasses the original answers in terms of both helpfulness and harmlessness;
(2) The refuse-to-answer pattern of GPT-4 created an area of overcorrected answers where both helpful and harmless scores are low, and our Aligner-7B improved these answers by providing additional information and corrections.
(3) The Alpaca-7B model, which is not aligned, had its answers corrected by our Aligner-7B, significantly increasing both scores.
(4) The Llama2-70B-Chat model is already aligned (the average safety score is higher than the correction in the training dataset), and the correction of Aligner-7B enhanced the helpfulness significantly while maintaining the harmless score.
For detailed performance result of Aligner models, please refer to Detailed Results.
This figure shows the distribution shift of helpfulness and harmlessness scores in the evaluation of checkpoint models of our Aligner-7B model. In the training process, the model has quickly learned the correction pattern in a relatively short time, and the learning process exhibits strong transparency and parameter efficiency.
Detailed Results
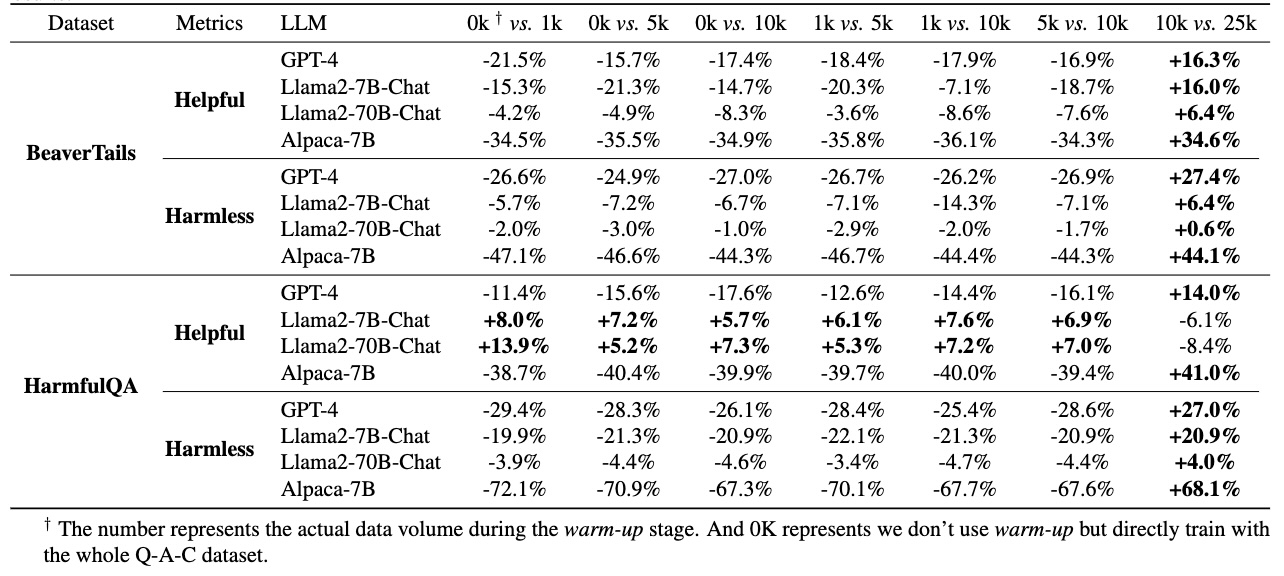
We first trained an identity Aligner for identity mapping, followed by extensive residual Q-A-C learning based on this Aligner. Specifically, we formed the Q-A-A dataset by extracting partial data from the training dataset in proportions of 2%, 10%, 20%, and 50%. The table presents our control experiments with a 50K training dataset, showing that extracting 20% of the data (i.e., 10K dataset size) for initial constant identity training yields relatively better results.

Constitutional AI (CAI) Constitutional ai: Harmlessness from ai feedback. , Self-Critique Self-critiquing models for assisting human evaluators , and Self-Refine Self-Refine: Iterative Refinement with Self-Feedback , primarily utilize the self-critiquing and refining capabilities of LLMs to enhance their performance. We employ CAI prompts solely during the inference time of LLMs to encourage self-revision of their answers. As demonstrated in the table above, our method, Aligner, outperforms the baseline considering both helpfulness and harmlessness dimensions. Additionally, baseline methods typically require multiple dialogue iterations and extended context windows for prompt insertion and ongoing self-correction. This could result in longer inference times and considerable consumption of context window length.

To demonstrate the independence of Aligner from specific datasets, we utilized various open-source RLHF preference datasets. Specifically, we trained on HH-RLHF Training a helpful and harmless assistant with reinforcement learning from human feedback. and PKU-SafeRLHF Beavertails: Towards improved safety alignment of LLM via a human-preference dataset. Safe rlhf: Safe reinforcement learning from human feedback. datasets and compared Aligner with SFT, RLHF, and DPO. After fine-tuning Alpaca-7B with SFT, RLHF, and DPO, we compare these models against the original Alpaca-7B corrected by Aligner. The experiment results (as shown in the table above) indicate that Aligner's performance in enhancing the original model's capabilities is comparable to, or exceeds, that of the baseline methods. Notably, models finetuned with RLHF or DPO tend to generate either conservative answers or fail to recognize dangers while adding helpful information explicitly. Importantly, training with RLHF or DPO methods requires optimizing significantly more models and consuming more training resources than just training an Aligner, e.g., for a 70B model, DPO needs 11.25 times and RLHF 22.5 times more resources than Aligner.
Applications
Multi-round RLHF training via Aligner
New Multi-round Training Pipeline
As a data augmentation tool, Aligner can enhance the upstream model's response \(A\) into an improved response \(A^*\), thereby forming a synthetic preference dataset. This dataset can be used to further train the upstream model via RLHF/DPO. Repeating this process allows for multi-round RLHF or DPO.
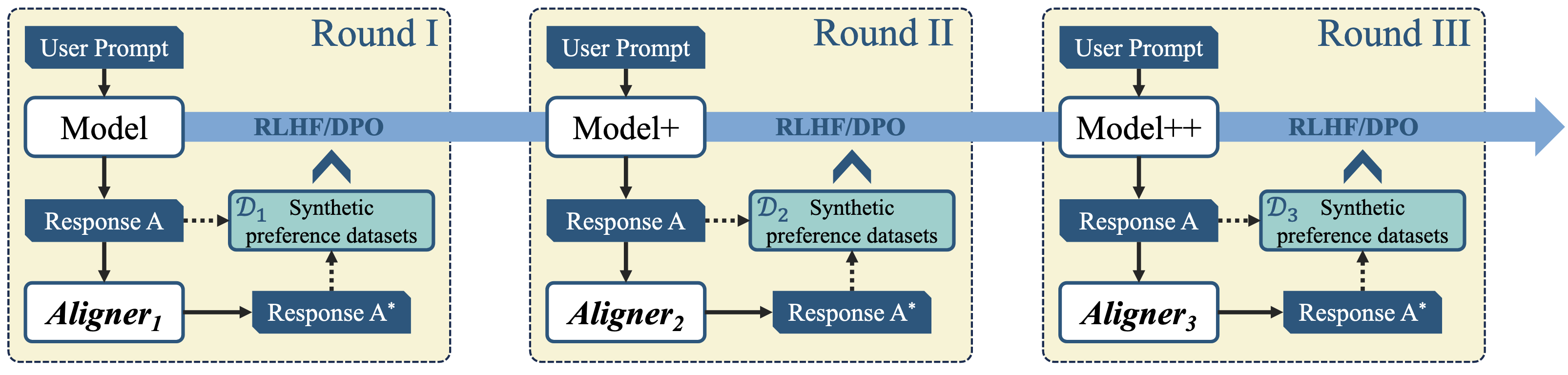
- The Aligner inherits the feature of transferring from the dispreferred distribution to the preferred distribution in the preference dataset.
- Aligner modifies the upstream model to produce better answers, bringing the distribution of resulting preference dataset closer to the answer distribution of the upstream model. This effectively mitigates the reward model collapse problem caused by out-of-distribution (OOD) preference datasets.
- The Aligner serves as a synthetic data generator, providing an efficient and repeatable method for constructing preference datasets.
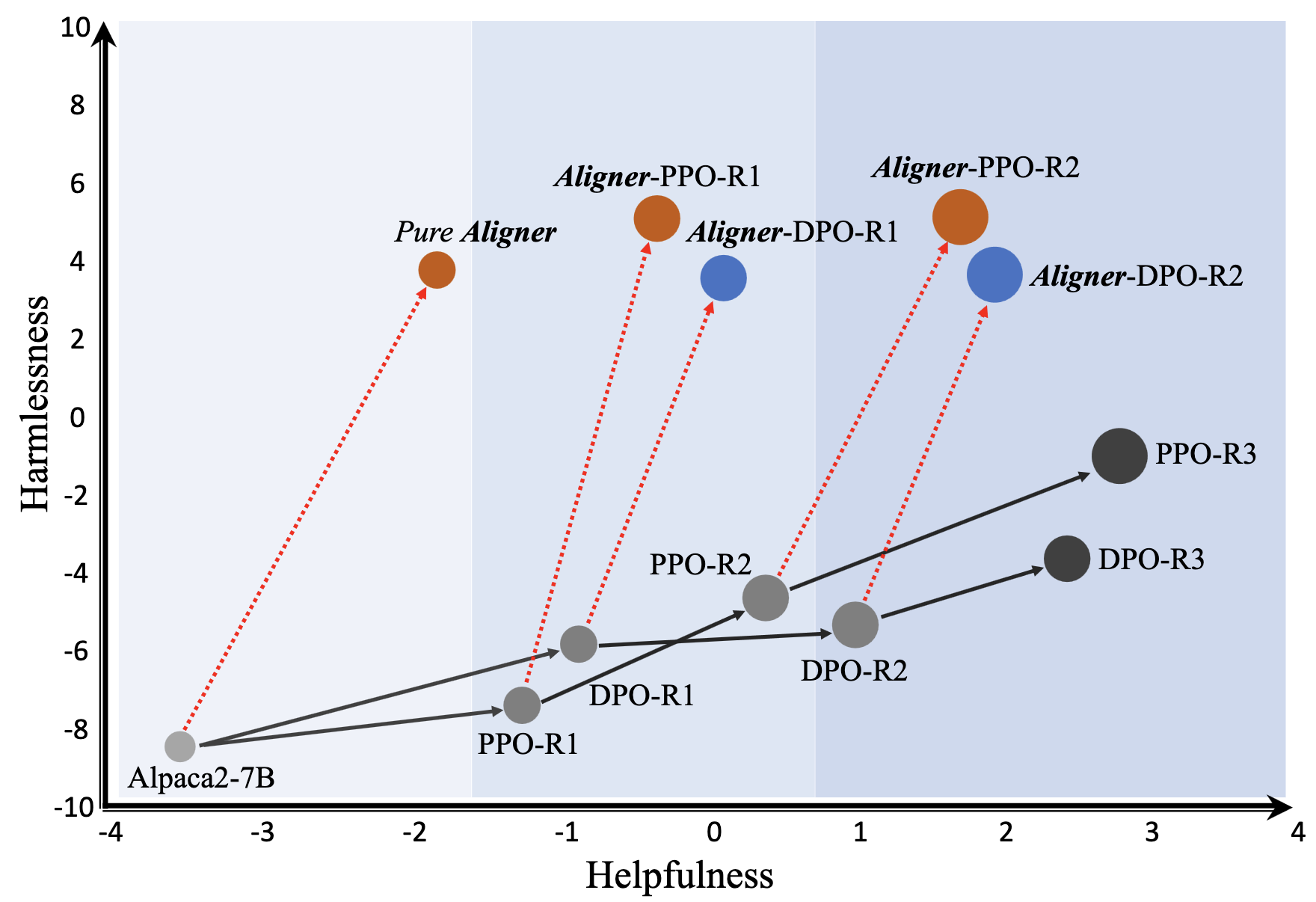
Performance
Weak-to-Strong Correction via Aligner
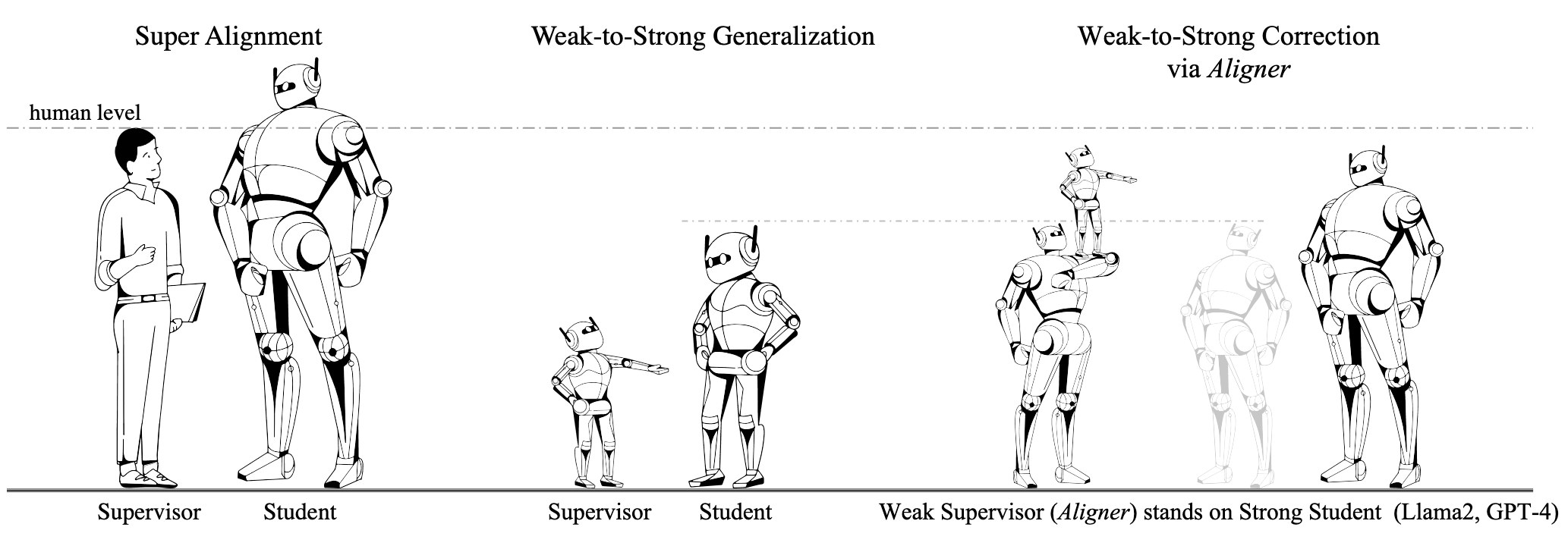
As AI systems reach human-level performance across various tasks and undertake increasingly complex activities that are hard for humans to grasp, it becomes progressively challenging to provide ongoing, reliable feedback and ensure that their behaviors align with human intentions. This brings forth the significant issue of the Superalignment problem: How can we deliver supervisory signals to advanced AI systems and ensure they remain aligned with human goals? AI Alignment: a Comprehensive Survey Concrete problems in AI safety. . Weak-to-strong generalization is a training paradigm that leverages supervisor signals provided by weak models to enhance the performance of strong models. The weak to strong paper Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. has conducted preliminary trials in NLP classification, chess puzzles, and reward modeling tasks, observing positive gains by simply fine-tuning strong pre-trained models using pseudo-labels produced by weak models. This paradigm is analogous to the concept of "teaching" where the weak model instructs the strong one.
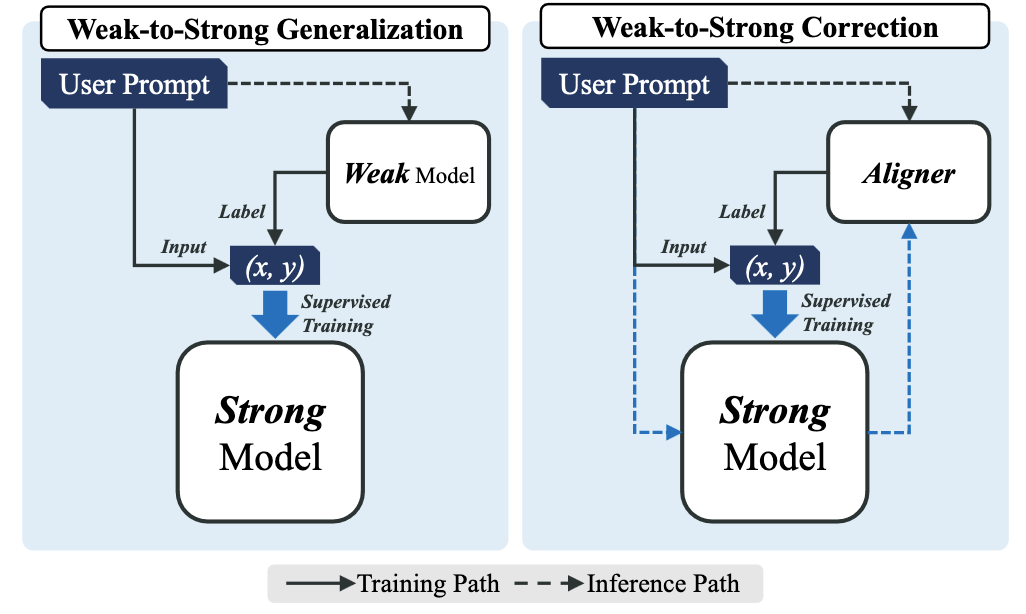
Illustration of our pipeline
Pipeline of Weak-to-Strong Correction
Performance
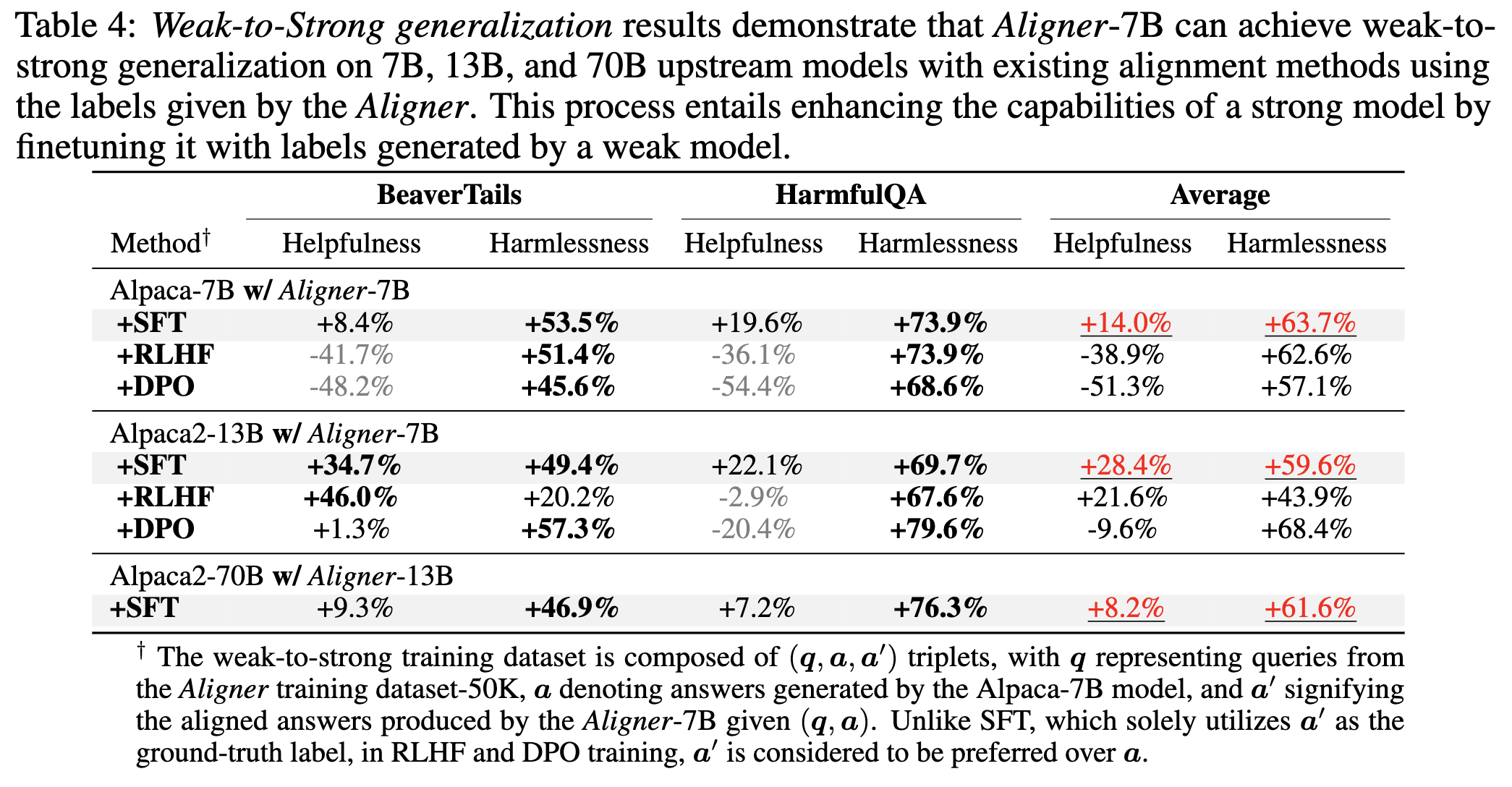
- The RLHF and DPO methods significantly improve the upstream model's performance on certain metrics. However, they do not completely surpass the strong model's original capabilities, particularly regarding decreased helpfulness. This decline is due to these models' tendency to conservative patterns (i.e., qualitative answers with less informational content). This suggests that the two-stage learning process of reward modeling and policy optimization, compared to SFT's direct label-based mapping, may introduce more feature noise and information loss, making accurate optimization more challenging.
- The RLHF method outperforms the DPO method in general. Given that the training data for weak-to-strong generalization is based on the output from the upstream model, subsequently aligned by Aligner-7B. The RLHF method shows better performance in this semi-online setting.
- The safety improvement is more substantial than that in helpfulness. Safety is easier to assess compared to helpfulness and can more readily be enhanced through simple rejection.
FAQ
Question #1: Aligner vs. SFT/RLHF/Prompt Engineering.
Aligner vs. SFT:
As illustrated in the Figure1 below, SFT directly creates a cross-domain map from Query semantic space to Answer semantic space. This process depends on the upstream model to infer and model various contexts in the semantic space, which is much harded than learning the correction signals. This is how we creat the "copy + correct" paradigm in Aligner. Aligner essentially creates a mapping from the Answer's semantic space to the Correction Answer's semantic space. We found that these two semantic spaces are closer in distribution, the Aligner training paradigm can be considered a form of residual learning (Residual Correction). Moreover, we derive data in varying proportions from the Q-A-C training dataset to create Q-A-A data, and used this Q-A-A data to train an Aligner in identity mapping (referred to as the warm-up step). Based on this, we then train with the entire Q-A-C training dataset. We observe that with a 50K dataset, the optimum performance is achieved when the warm-up proportion is 20%. Additionally, Aligners subjected to the warm-up training strategy typically outperform those trained directly with the full dataset without a warm-up phase. At a very high level, ResNet also employed this concept of copy with residual to address the training challenges associated with the increasing neural network depth.
Aligner vs. RLHF:
Aligner achieves alignment without relying on Reinforcement Learning from Human Feedback (RLHF) Training language models to follow instructions with human feedback. . RLHF utilizes pre-collected human preference data to train a reward model. The reward model provides signals to RL algorithms like PPO Proximal policy optimization algorithms. , guiding the optimization of the model's behavior to align more closely with human expectations. However, RLHF poses significant challenges in practical applications, especially in parameter tuning and its fluctuating effects, complicating the alignment of LLMs Training language models to follow instructions with human feedback. Safe rlhf: Safe reinforcement learning from human feedback. Llama 2: Open foundation and fine-tuned chat models. . Specifically, the reward model's task of mapping human preference data from discrete to continuous numerical space for optimization presents challenges in training methods and robustness. Unlike sequence-to-sequence (Seq2Seq) models with robust generalization in text space, numerical models such as reward models exhibit weaker text space generalization, contributing to RLHF's instability. Aligner introduces a new alignment paradigm, training a Seq2Seq model to identify the differences (residuals) between aligned and misaligned answers. Aligner offers several significant advantages over RLHF:
1.Aligner achieves noticeable alignment with less training data. For instance, with 50K training data, Aligner trained a 7B model, enhancing GPT-4's helpfulness by 19% and safety by 26%, and boosting Vicuna 33B's helpfulness and safety by 51% and 56%, respectively.
2.Aligner offers a simpler training process. It trains a Seq2Seq model for alignment, a more straightforward and manageable process than RLHF's complex reward model learning and RL fine-tuning. RLHF's engineering tuning intricacies and the inherent instability and hyperparameter sensitivity of RL algorithms make its implementation challenging, while Aligner's simplified approach substantially reduces complexity.
3.Unlike RLHF, Aligner does not require access to model weights. While RLHF is effective in model alignment, it depends on direct model training. The applicability of RLHF is limited with non-open-source API-based models and their specific downstream task fine-tuning requirements. In contrast, Aligner does not require direct manipulation of the model's original parameters. Aligner externalizes alignment needs to an independent module, offering a flexible method.
4.Aligner is not limited by model type. Under RLHF, fine-tuning different models like Llama2 Llama 2: Open foundation and fine-tuned chat models. , Alpaca Stanford alpaca: An instruction-following llama model. , or Vicuna Vicuna: An open-source chatbot impressing gpt-4 with 90% chatgpt quality. requires re-collecting preference data and adjusting training parameters in the reward model training and RL phase. Aligner supports any model's alignment with just one-time training. For instance, one-time Aligner training in research improved helpfulness and safety for 11 different models, showcasing its wide generalization capabilities.
5.Aligner offers greater flexibility in training resource requirements. Fine-tuning a 70B model using RLHF demands significant computing resources, often needing hundreds of GPU cards. Specifically, RLHF requires loading not just the 70B parameter target model, but also additional reward, Actor, and Critic models with similar parameter sizes. Consequently, RLHF consumes more computing resources per unit time than pre-training. In contrast, Aligner's training strategy is more flexible, enabling users to select the scale of Aligner training based on their available computing resources. For instance, to align a 70B model, users can choose from various Aligner model scales, like 7B, 13B, or 70B, based on available resources. This flexibility reduces the overall demand for computing resources and enables efficient alignment even with limited resources. Thus, Aligner, adaptable in its training resource requirements, offers an effective, practical strategy for large-scale model alignment, providing various options for users or researchers under different resource constraints.
Aligner vs. Prompt Engineering (i.e. Self-Correction):
Prompt Engineering is a widely used method to boost large language models' capabilities, but it faces several significant issues: 1.Designing prompts is challenging, requiring distinct designs for various models, and the effectiveness hinges on each model's capabilities. If a model's abilities fall short for a task, multiple iterations might be required. 2.This approach wastes the context window, as small models' limited context affects performance and overly long contexts hike costs for large models. In contrast, Aligner achieves goals in one step and is not limited by model type. With just one-time training, Aligner supports the alignment of any model. For example, research shows that one-time Aligner training enhanced helpfulness and safety across 11 different models, demonstrating its broad generalization capabilities. Moreover, Aligner saves the precious context window. Additionally, combining it with Prompt Engineering can yield better results. Specifically, we use prompt in CAI.
Question #2: How does the correction paradigm work in Aligner and why it outperforms SFT?
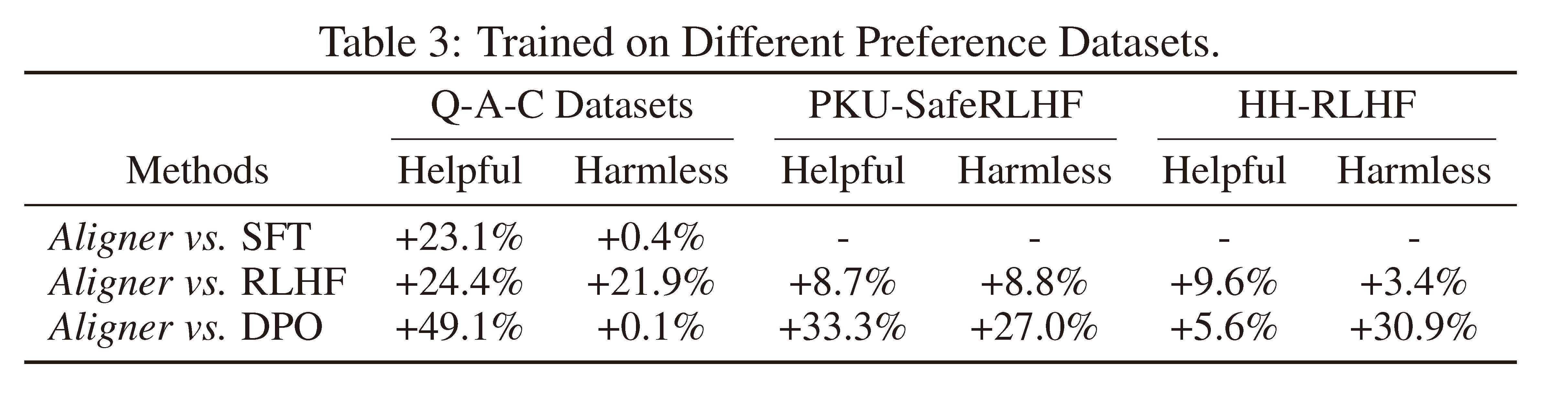
From the perspective of performance, SFT will, to some extent, alter the capabilities and knowledge of the front-end model, potentially reducing the helpfulness of its outputs. The Aligner makes the alignment task independent of the upstream model, allowing it to preserve the knowledge and performance of the front-end model without negative impact. Simultaneously, for originally well-formulated answers, the Aligner aims to either maintain the original response or enhance it with more helpful details, which will enhance the helpfulness of original answer.
Question #3: Aligner shows significant improvement on GPT-4, does it involve potential data leakage problems?
Given the concern about data leakage, we handled the training and evaluation data with utmost care and caution. Multiple checks were performed for duplicates between the evaluation and training dataset prompts to ensure no leakage of evaluation data.
Specifically, we initiate our dataset creation process by conducting query deduplication on sources, e.g., the Stanford Alpaca https://huggingface.co/datasets/tatsu-lab/alpaca , user-shared conversations from ShareGPT https://sharegpt.com/ , HH-RLHF https://huggingface.co/datasets/Anthropic/hh-rlhf and others. We finally get a set of 27K queries for the following training dataset creation. Subsequently, we use various open-source models e.g., Alpaca-7B, Vicuna-(7B,13B), Alpaca2-(7B,13B) We fine-tuned Llama2-(7B,13B) using Stanford Alpaca's 52K dataset to get models that only have instruction-following capability without safety alignment, namely Alpaca2-(7B,13B). , and Llama2-(7B,13B)-Chat to generate responses to these queries, yielding the following data statistics: Following quality filtering and duplicate removal, we ultimately obtain a Query-Answer dataset of 57K pairs for subsequent correction-answer annotation. Finally, we use GPT-4, Human and larger models to annnotate correction answer.
Our evaluation dataset includes selections from BeaverTails Beavertails: Towards improved safety alignment of LLM via a human-preference dataset. and HarmfulQA Red-Teaming Large Language Models using Chain of Utterances for Safety-Alignment. , among which BeaverTails has been accepted by NeurIPS2023 and HarmfulQA has been widely used by community. Particularly, before confirming the final dataset used for evaluation, we conducted a duplication screening and search of the prompts used for evaluation against the prompts in the training dataset, ensuring there were no duplicate data, thereby avoiding the issue of data leakage.
Our training code has already been open-sourced. Subsequently, we will open-source both complete datasets and various scaled versions of the Aligner model after review for community use and verification.
Question #4: The training data contain GPT-4 annotations, why does Aligner still improve the GPT-4?
From a mechanistic perspective, the training mechanism of Aligner satisfies the primary hypothesis: Correction is generally easier than generation, which makes the Q-A-C (Query-Answer-Correction) training mechanism adopted by Aligner easier to fit the distribution patterns in the training data. Our Aligners are trained in the following mechansim: we first establishes an identity mapping mechanism from Q-A to A, then conducted a residual mapping learning method for Q-A-C. This method is superior to directly training the model to generate responses. Compared to traditional cross-domain mapping from query space to answer space, the correction mechanism establishes an intra-domain mapping between Answer and Correction Answer, producing responses that are superior to direct answer generation. This is consistent with the ideas of baseline methods like Constitutional AI Constitutional ai: Harmlessness from ai feedback. , and outside the alignment field, ResNet Deep residual learning for image recognition. also uses a similar approach to mitigate the accuracy decline and convergence difficulties caused by increased neural network depth.
From the perspective of results, GPT-4, as an API-based mode that has undergone safety alignment, will generative more conservative responses [3,4,5]. Since learning refusal response pattern is more accessible than learning to generate safe responses with more helpful information, LLMs that have undergone safety alignment all have the above problem. In constrast, by learning the redisual gap between correction answer and unaligned answer, Aligner tend to provide as much as helpful information as possible without generating toxic outputs. This also demonstrates the Aligner's potential as new paradigm for alignment. Additionally, for already safe responses from GPT-4, our Aligner can add more specific details, further enhancing the helpfulness of the original response.
Question #5: How does the Weak-to-Strong generalization work through Aligner?
Weak-to-Strong generalization Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. explores whether training a strong model with weak model labels can enhance its performance. OpenAI's approach plays a significant role in addressing the SuperAlignment problem Concrete problems in AI safety. . During the training process, a weak model is initially trained with ground truth data. For instance, in text classification tasks, the dataset is split into two: the first half, consisting of input and ground truth, trains the weak model; the second half retains only the input, using labels generated by the weak model (the weak labels). During this training, the strong model receives supervision solely from the weak labels generated by the weak model. Training the weak model with ground truth equips it to tackle corresponding tasks; however, the inputs for generating weak labels differ from those used in training.
Figure 3 illustrates our novel perspective on the weak-to-strong generalization. Our Aligner acts as a "Supervisor standing on the shoulders of giants." In contrast to OpenAI's direct supervision of "giants," our Aligner is composed with larger model, offering more accurate labels for training stronger models, namely weak-to-strong correction. In the Aligner's training process, correction data are annotated by GPT-4, human annotators, and larger models as training labels, which is consistent with OpenAI paradigm . Subsequently, we use Aligner to generate weak labels (i.e., Corrections) on a new Q-A dataset. These labels serve as supervision signals to train larger models, leading to further improvements, as Table 2 demonstrates.
Question #6: Is it possible to put multiple Aligners together?
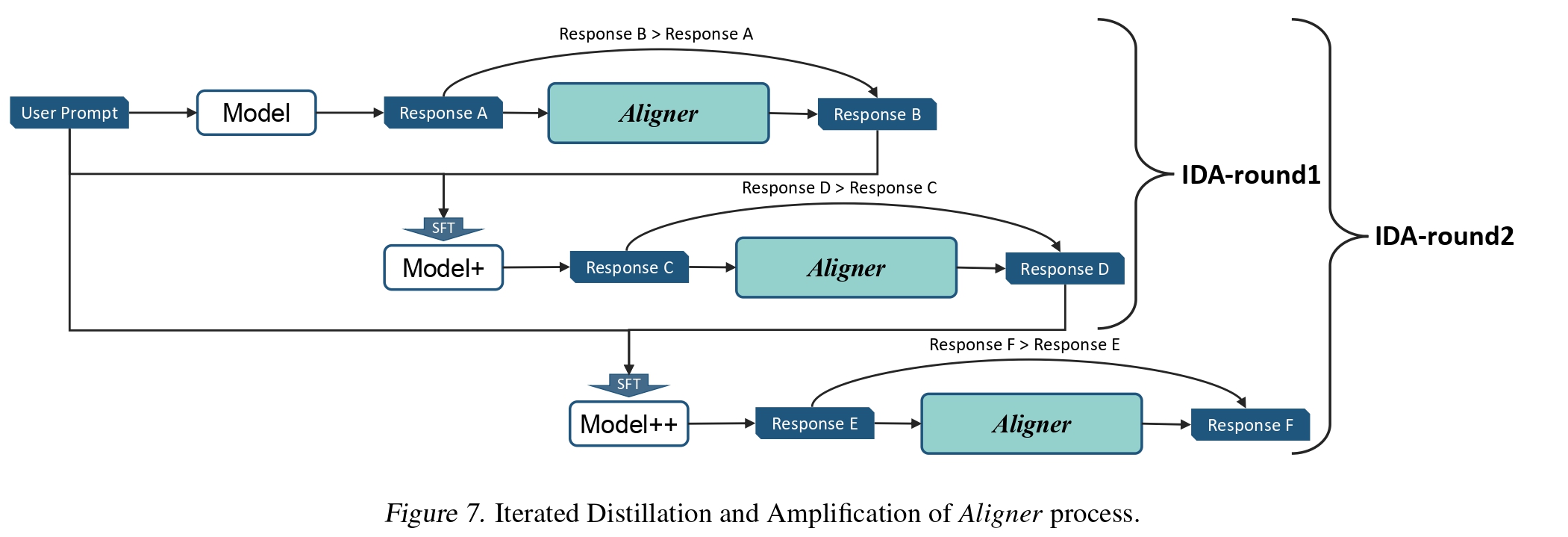
Aligners, being stackable, enable the iteration from weak-to-strong generalization. In this process, a layer of Aligner functions as an amplifier. Subsequently, the weak label generated by this Aligner is utilized for SFT training, specifically during the distillation step. In fact, before the distillation step, nesting multiple layers of Aligners can shift the distribution of the original answer towards the Correction Distribution, leading to improved effects.
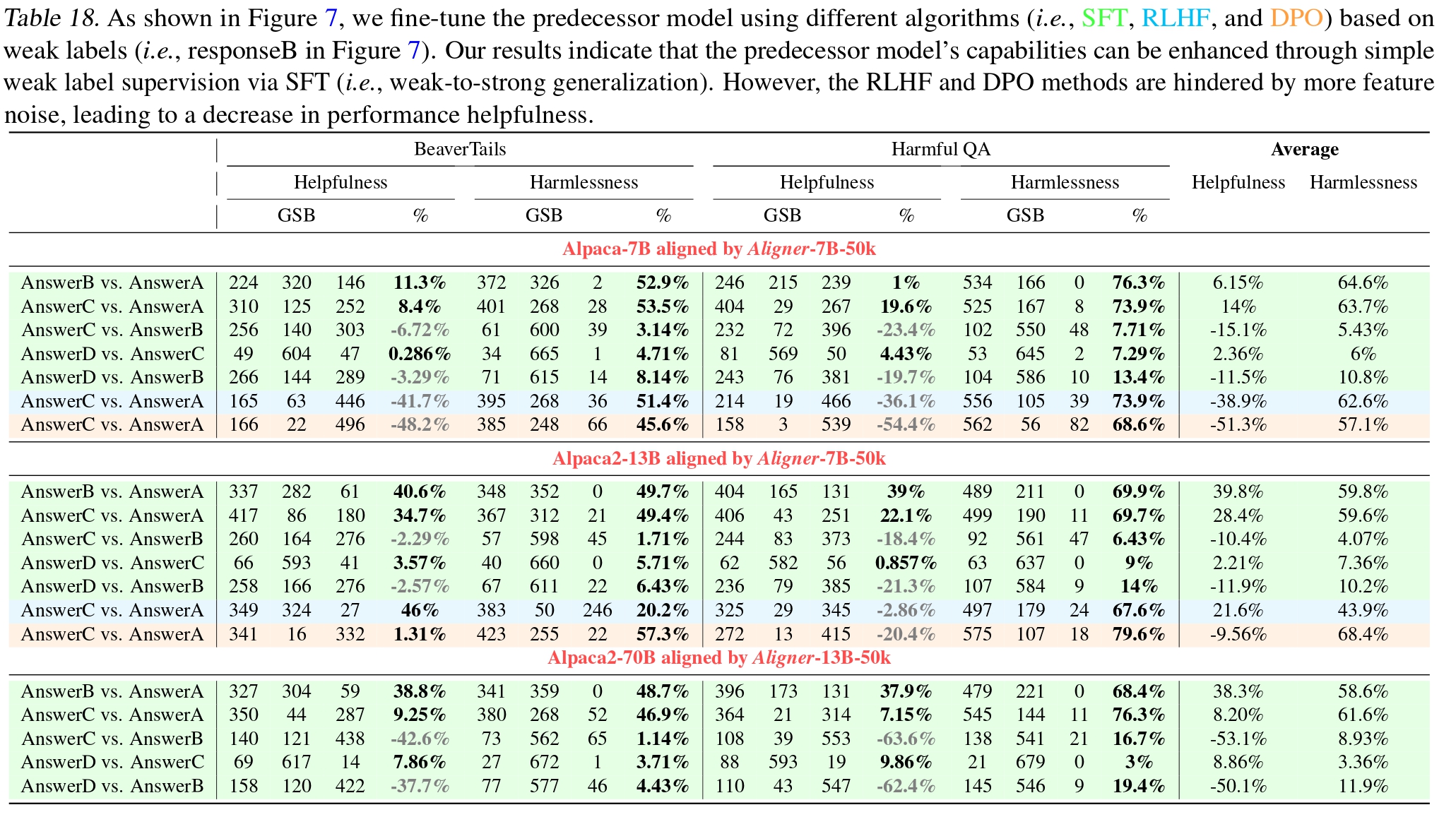
Simultaneously, Aligner offers a potential framework for Iterated Distillation and Amplification (IDA) Supervising strong learners by amplifying weak experts. , as illustrated in Figure 7 below. The Aligner can serve as an Amplifier to enhance the model post-distillation, with the enhanced output being suitable for further distillation. The experimental results are presented in Table 18 below. Regarding helpfulness and harmlessness, this IDA implementation showed iterative progress in harmlessness, but a decline in helpfulness. This trend is attributed to the model's conservative output during distillation, a result of information loss, yet the framework remains promising for IDA implementation. Future efforts will concentrate on enhancing distillation efficiency and broadening the scope of Aligner applications.
Question #7: Why we care only about LLM's helpfulness and harmlessness? Does Aligner work in any other aspects?
When measuring the alignment of LLMs with human values and intentions, one of the widely accepted criteria is the 3H principles (Helpful, Harmless, Honest) Training a helpful and harmless assistant with reinforcement learning from human feedback. .However, the evaluation of honesty is more challenging. Therefore, we chose two widely accepted dimensions for evaluation: Helpfulness and Harmlessness. We selected datasets from two published works: Beavertails Beavertails: Towards improved safety alignment of LLM via a human-preference dataset. and HarmfulQA Red-Teaming Large Language Models using Chain of Utterances for Safety-Alignment. as our evaluation datasets. Beside our paper, many classic works such as InstructGPT Training language models to follow instructions with human feedback. , Constitutional AI Constitutional ai: Harmlessness from ai feedback. and SafeRLHF Safe rlhf: Safe reinforcement learning from human feedback. also adopted these two dimensions of Helpfulness and Harmlessness for evaluation.Meanwhile, we explored and verified the consistency between GPT-4 assessments and human assessments. In this process, GPT-4 made preliminary partial-order judgments on responses A and B based on given prompts, and provided detailed reasoning. Based on this, our annotation team conducted a secondary verification to ensure the accuracy of the evaluation results. In addition, we specifically designated quality inspectors to spot-check the evaluation process to ensure the high standards and reliability of the evaluation results.

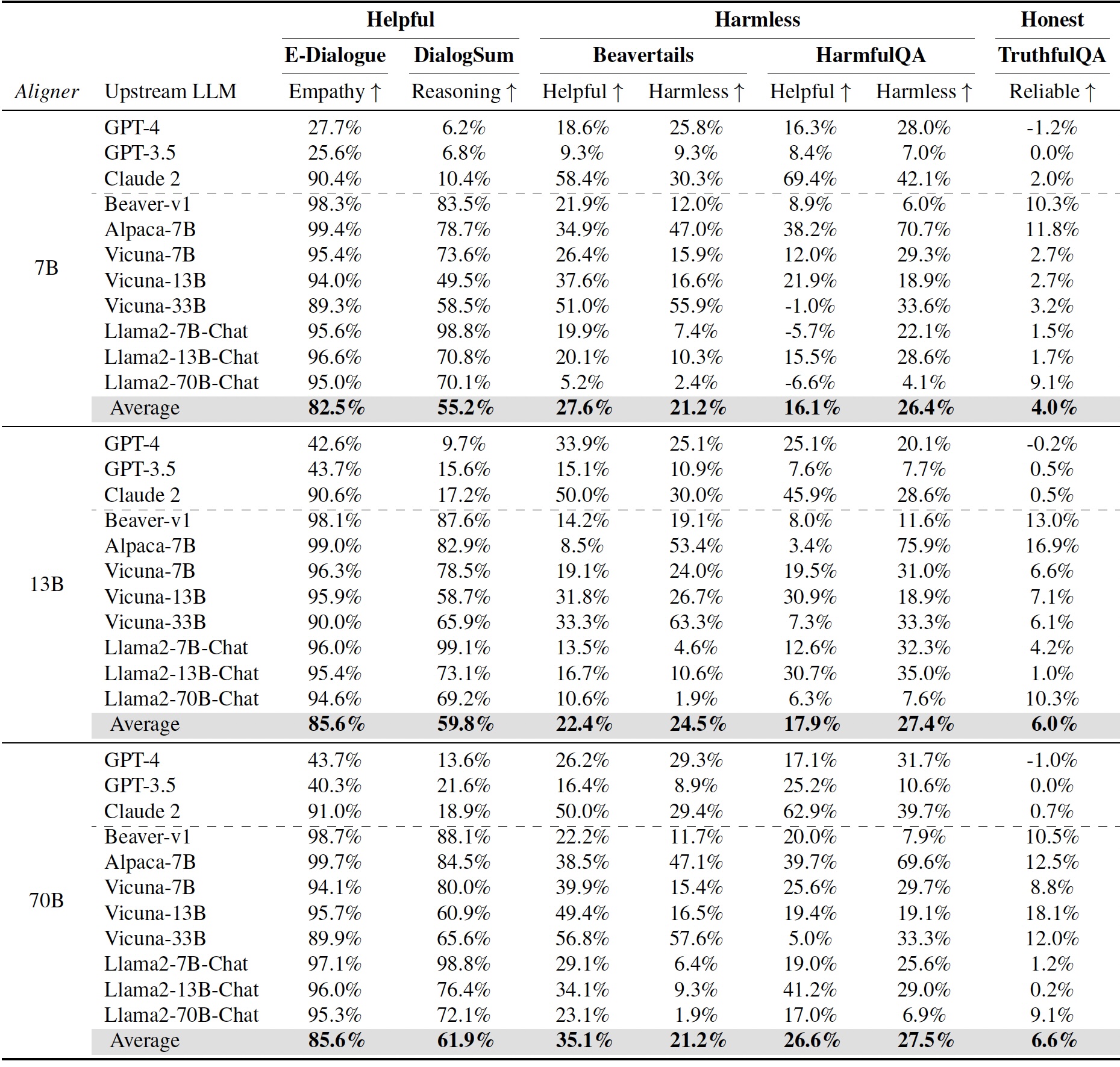
We further validated Aligner's ability to incorporate other to-align aspects. Following the design of Empathetic Dialogue dataset Towards Empathetic Open-domain Conversation Models: a New Benchmark and Dataset. , we selected a 4K training set and a 1.5K test set from its public available dataset (ensuring the dataset is used appropriately and is free of leakage). We utilized the train set to perform finetune on Aligner-7B and Aligner-13B to enhance their empathetic abilities. The fine-tuned Empathy-Aligner-7B and Empathy-Aligner-13B were not only able to improve the empathetic capacity of more than 50% of GPT-4's responses, significantly surpassing the original Aligner model, but also saw an improvement in helpfulness after finetuning. Detailed experimental results are shown in the Table 16 above. This experiment demonstrates the Aligner models' outstanding capabilities in other domains and the low cost and high efficiency of adding features to Aligners. Detailed information can be found in the paper Appendix C.5.
Question #8: Potential research directions and applications based on Aligner.
Aligner, as a novel alignment method, possesses significant research potential. For instance, Aligner can be applied in the following scenarios:Application of Aligner in multi-turn dialogue scenarios. In this context, the challenge of sparse rewards is particularly significant. In question-and-answer (QA) dialogues, scalar supervision signals are typically obtained only after the dialogue concludes. This sparsity issue becomes more pronounced in multi-turn dialogues, like continuous QA scenarios, where RLHF is less effective. Investigating Aligner's potential in enhancing alignment in multi-turn dialogues represents a valuable research area.
1. Aligning human values with reward models poses a significant challenge in the multi-stage process of building reward models based on human preferences and fine-tuning LLMs, particularly in ensuring the alignment of LLMs with specific human values like fairness and empathy. Delegating the value alignment task to an external Aligner module and training it with specific corpora offers a novel approach to value alignment. It also enables the Aligner to modify the outputs of preceding models to better reflect specific values.
2.Streamlining and parallel processing of Aligner (MoE Aligner) is a promising direction. Specializing and integrating Aligners in various directions can lead to a more powerful and comprehensive MoE Aligner, fulfilling a range of mixed safety and value alignment needs. Additionally, enhancing the parallelism of Aligner to reduce inference time loss represents another viable direction.
3.Integration during model training involves incorporating an Aligner layer after certain weight layers, enabling real-time intervention in model outputs during training. This method not only enhances alignment efficiency but also optimizes the model training process, leading to more effective model alignment.
4.Since Aligner is insensitive to model agnostic parameters, a potential application of Aligner is as a Safety Layer and a patch for LLMs. Just like a security butler in a computer operating system, Aligner can act as the "security butler" for LLMs, correcting dangerous and unsafe content in the output of LLMs in a timely manner, applying patches to ensure the normal use of the system. Compared to SFT, Aligner does not affect the performance of the preceding model, is plug-and-play, and consumes fewer training resources, making it more feasible than SFT.